Закрыты дубли в вордпресс. Как избавиться от дублей WordPress
» я рассказывал, что такое дубли и как их можно найти. В этой статье я хотел бы осветить тему того, как можно убрать дубли с Вашего сайта, воспользовавшись рядом плагинов или обычным кодом. Сразу хотелось бы сказать, что индексацией дублей в основном страдает поисковая система (ПС) Google, даже не смотря на то, что они запрещены в файле robots.txt . ПС Яндекс работает по своему алгоритму и меньше воспринимает подобный контент. Итак, приступим.
Дубли ответов на комментарии — replytocom
Самые распространенные дубли в WordPress — это так называемый replytocom , который появляется, когда на сайте включены древовидные комментарии. Если приглядеться на ссылку «Ответить на комментарий», то можно проследить наличие данного вида дублей. С одной стороны это удобно, ведь пользователь может ответить на чей либо комментарий и видеть структуру ответов. С другой стороны это очень пакостная вещь, поскольку replytocom порождает ни один, а как правило несколько дублей. К примеру, на Вашем сайте есть 500 комментариев, значит имеется как минимум 500 дублей.
Для того, чтобы убедиться в наличие дублей replytocom , можно перейти по следующему URL адресу: http://sitename.ru/название_поста?replytocom=какое_то_число. Теперь в адресной строке можно наблюдать что то подобное этому: http://sitename.ru/название_поста/#comment=какое_то_число.
Кроме того, в WordPress существуют еще ряд дублей, к которым относятся:
- feed;
- page;
- comment-page;
- attachment;
- attachment_id;
- category;
- trackback.
Каждый вид дублей соответствует техническим возможностям движка. Проверить их можно при помощи оператора site , о котором написано в .
Убираем дубли при помощи плагинов
На моей практике, мне приходилось пользоваться 3-я видами плагинов, которые помогают избавиться от дублей в WordPress.:
- All in One Seo Pack . После установки в разделе Общие настройки нужно поставить галочку Канонические Url .
- Yoast Seo . В настройках плагина ставим галочку Убрать replytocom ;
- Ark hidecommentslinks . Данный плагин позволяет закрыть ссылки на сайты комментаторов, а также убрать replytocom из ссылки ответа на комментарий. Не имеет настроек.
Убираем дубли при помощи кода
Чтобы убрать дубли при помощи кода нужно отредактировать 3 файла — robots.txt , .htaccess и functions.php . Для тех кто не знает, первые два файла находятся в корне сайта, а третий файл лежит в папке с активной темой.
В статье « » я писал о том, как его правильно настроить. Некоторые же оптимизаторы советуют изменить содержимое robots.txt на следующее:
User-agent: * Host: sitename.ru Disallow: /wp-feed Disallow: /wp-includes Disallow: /wp-content/cache Disallow: /wp-content/plugins Disallow: /wp-content/themes Sitemap: http://sitename.ru/sitemap.xml User-agent: YandexImages Allow: /wp-content/uploads/ User-agent: Googlebot-Image Allow: /wp-content/uploads/
Вместо sitename.ru должен быть прописан домен Вашего сайта.
На следующем шаге открываем файл.htaccess и после строки RewriteRule ^index\.php$ - [L] добавляем следующий код:
RewriteCond %{QUERY_STRING} ^replytocom= RewriteRule (.*) $1? RewriteRule (.+)/feed /$1 RewriteRule (.+)/attachment /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/trackback /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1?
Теперь, что еще осталось сделать, это добавить следующий код в файл functions.php:
Function add_meta_noindex_nofollow () { if (is_paged()) { echo "".""."\n"; } } add_action("wp_head", "add_meta_noindex_nofollow", 3);
Код вешаем на хук wp_head , и теперь на страницах с пагинацией будет выводиться meta-тег, запрещающий их индексацию.
И чем они опасны. Сегодня мы узнаем как избавиться от дублей страниц раз и навсегда.
В WordPress есть отдельная категория дублей страниц, которые образуются из-за технических особенностей системы и присутствуют только в Google. Такие повторения сложно заметить на сайте и еще сложнее самостоятельно удалить. Радуйтесь, что вы читаете эту статью, потому что сейчас я вас всему научу!
Простой способ убрать дубли страниц
Если вы давно занимаетесь техническим совершенствованием своего блога, то наверняка уже сделали самые простые шаги, предотвращающие появление дублей. Проверьте себя:
Хорошо, если у вас сделаны эти три простейших пункта, но это еще не значит, что вы знаете, как удалить дубли страниц. Все самое интересное впереди.
Что такое дубли страниц WordPress replytocom и другие?
Если ваш блог сделан на WordPress, у вас наверняка присутствуют следующие типы дублей страниц:
- replytocom
- comment-page
- attachment
- attachment_id
- category
- trackback
Каждый из этих типов связан с определенной технической возможностью WordPress. Определить, какие из них есть у вас можно с помощью оператора site, об этом очень подробно написано в прошлой статье - .
Например, если добавить в конце урла любой статьи /feed, откроется xml версия статьи для - ее текст тот же самый, но адрес отличается. Replytocom используется в древовидных комментариях при нажатии кнопки «Ответить». Выходит, что каждый комментарий создает дополнительный url одной и той же страницы. А если у статьи тысяча комментариев, то и дублей у нее будет 1000.
С такими дублями страниц срочно нужно бороться, потому что сайт с подобной проблемой мгновенно попадает под .
Почему именно Гугл, я уже объясняла. Все дело в файле robots.txt. Когда в нем закрыт доступ к чему-то, Google все равно забирает это в выдачу. Просто не показывает содержимое:

Чтобы этого избежать, нужно наоборот открыть Гуглу доступ ко всему в файле robots.txt, при этом в head каждого файла добавить :
User-agent: * Host: my-site.ru Disallow: /wp-feed Disallow: /wp-includes Disallow: /wp-content/cache Disallow: /wp-content/plugins Disallow: /wp-content/themes Sitemap: https://my-site.ru/sitemap.xml User-agent: YandexImages Allow: /wp-content/uploads/ User-agent: Googlebot-Image Allow: /wp-content/uploads/
Поменяйте my-site.ru на свой адрес. Теперь роботу разрешено заходить на любые страницы сайта.
| 1 2 3 4 5 6 7 8 9 | RewriteCond %{QUERY_STRING} ^replytocom= RewriteRule (.*) $1? RewriteRule (.+)/feed /$1 RewriteRule (.+)/attachment /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/trackback /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1? |
RewriteCond %{QUERY_STRING} ^replytocom= RewriteRule (.*) $1? RewriteRule (.+)/feed /$1 RewriteRule (.+)/attachment /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/trackback /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1?
Это набор 301-редиректов. Теперь при попытке робота зайти на страницы типа site.ru/post-name/feed/ его перебросит на оригинальную страницу типа site.ru/post-name/ .
/* Вставляет мета-тег роботс noindex,nofollow постраничного разбиения */ function my_meta_noindex () { if (is_paged() // Все и любые страницы пагинации) {echo "".""."\n";} } add_action("wp_head", "my_meta_noindex", 3); // добавляем свой noindex,nofollow в head
Теперь на страницах c постраничным разбиением записей (например, https://сайт/page/2 ) поисковик наткнется на запрещающий индексацию мета-тег и не будет показывать страницу в выдаче. Этот пункт я ставлю под сомнение, т.к. многие оптимизаторы считают, что нельзя закрывать от индексации страницы с анонсами статей блога. Выполнять данный пункт или нет, решайте сами.
 Этими настройками плагин All in One Seo Pack автоматически добавил мета-тег «robots» на страницы с тегами и рубриками. Не пришлось делать это вручную, как для страниц с пагинацией записей.
Этими настройками плагин All in One Seo Pack автоматически добавил мета-тег «robots» на страницы с тегами и рубриками. Не пришлось делать это вручную, как для страниц с пагинацией записей. Это нужно для того, чтобы комментарии не делились постранично. Тогда и не появятся новые адреса для тех же страниц.
Это нужно для того, чтобы комментарии не делились постранично. Тогда и не появятся новые адреса для тех же страниц.Готово! Вы узнали, как удалить дубли страниц WordPress. Осталось дождаться переиндексации и проверить, уменьшилось ли количество страниц вашего сайта в индексе Google. Если вы сделали все согласно инструкции, то успех гарантирован!
Жду ваших вопросов в комментариях. Всем успехов в улучшении своего ресурса.
Привет! Известно, что наш любимый неустанно плодит дубли картинок, которые мы добавляем в посты на своем блоге. И в этой статье, я хочу рассказать, как можно удалить эти дубли и запретить их дальнейшее размножение.
А теперь, если посчитать месяцы до сегодняшнего дня, то получается, что прошло 52 месяца. Возьмем, к примеру, что за один месяц WordPress создал 100 дублей, тогда получается, что на моем блоге сейчас около 5200 ненужных картинок.
А у Вас этих дублей может быть в два, или три раза больше, если Вы давно ведете свой блог, и часто пишете статьи. Я давно хотел заняться чисткой картинок на своем блоге, но решил сделать это только сегодня.
Для удаления ненужных изображений, можно применить плагин «DNUI Delete not used », но я бы не советовал им пользоваться. Я вообще не советовал бы пользоваться каким-либо плагином для этих целей.
Некоторые люди удаляли изображения с помощью плагинов, а потом об этом сильно жалели, потому что не делали резервную копию. Плагин просто удалял иногда и нужные картинки.
Удалять картинки лучше вручную, хотя это и нудный процесс, но я Вам покажу, как это сделать быстро.Работу эту надо проделать всего один раз.
Даже, если Вы случайно удалите нужное изображение, то его можно будет быстро восстановить. В конце статьи можно посмотреть видео.
Дубли изображений, можно удалять непосредственно на самом хостинге, или на своем компьютере – это решать Вам. Я бы советовал заниматься этим на компьютере, чтобы картинки можно было удалять массово, а не по одной.
Итак, переходим на свой хостинг, и скачиваем все изображения на компьютер. Нам нужно скачать папку UPLOADS, которая находится по следующему пути: ВАШ_ДОМЕН/wp-content/uploads. Делаем дубликат этой папки, чтобы у нас была резервная копия, а с другой папкой будем работать.
Открываем любую папку с картинками и находим файлы, где указан размер изображения, например, shkola-frilansa-150x150.jpj. Все эти изображения нужно удалить, потому что это – дубли.

Не переживайте, если удалите несколько нужных картинок. Мы ведь сделали резервную копию, помните?
Но, если Вам будет встречаться размер 144x144, то его лучше не удалять, потому что WordPress этот размер использует.
Несколько месяцев назад, я отключил создание дублей в настройках блога, но размер 144x144 все равно создается автоматически, поэтому его лучше не трогать, или попробовать удалить, а потом проверить.
Итак, удалили все файлы, в которых указан размер изображения, а теперь папку UPLOADS, с которой работали, надо закачать обратно на хостинг, и проверить, все ли в порядке, и все ли изображения на месте.
Проверяем блог после удаления дублей изображений на WordPress
Но если вкратце, то этот плагин находит все битые ссылки на блоге. И, если мы удалили нужное изображение, которое WordPress использует, плагин об этом известит.
Переходим «Настройки » > «Проверка ссылок », и в настройках плагина открываем вкладку «Дополнительно ». Внизу жмем кнопку «Перепроверить все страницы » и какое-то время ждем, пока не завершится проверка.
Если после проверки плагин не нашел битых ссылок, значит Вы все сделали правильно, и можно расслабиться, но если битые ссылки будут выявлены, тогда просто загрузите нужные изображения обратно. Например, плагин нашел битую ссылку, тогда нужно будет вернуть на место файл shkola-frilansa-144x144.jpj в папку, которая указана в ссылке.
Посмотрите видео, как легко удалить дубли изображений в WordPress
Доброго времени суток!
Дубликаты страниц , или дубли — одна из тех проблем, о которой не подозревают многие вебмастера. Из-за такой ошибки, некоторые полезные WordPress-блоги теряют позиции по ряду запросов, и порою их владельцы даже не догадываются об этом. Каждый видит в статистике, что посещаемость веб-страницы упала, но разыскать и исправить ошибку могут не все. В этой статье пойдет речь о том, как найти дубли страниц сайта.
Что такое дубликаты страниц?
Дубли – это две и больше страниц с одинаковым контентом, но разными адресами. Существует понятие полных и частичных дублей. Если полные — это стопроцентный дублированный контент исходной (канонической ) страницы, то частичным дублем может стать страница, повторяющая ее отдельные элементы. Причины появления дублей могут быть разными. Это могут быть ошибки вебмастера при составлении или изменении шаблона сайта. Но чаще всего дубли возникают автоматически из-за специфики работы движков, таких как WordPress и Joomla. О том, почему это происходит, и как с этим справляться я расскажу ниже. Очень важно понимать, что вебсайты с такими повторениями могут попасть под и понижаться в выдаче, поэтому дублей стоит избегать.
Как проверить сайт на дубли страниц?
Практика показывает, что отечественный поисковик Яндекс относится к дублям не так строго, как зарубежный Гугл. Однако и он не оставляет такие ошибки вебмастеров без внимания, поэтому для начала нужно разобраться с тем, как найти дубликаты страниц.
Во-первых, нам нужно определить, какое количество страниц нашего сайта находится в индексе поисковых систем. Для этого воспользуемся функцией site:my-site.ru, где вместо my-site.ru вам нужно подставить свой url. Покажу, как это работает на примере своего блога. Начнем с Яндекса. Вводим в строку поиска site:сайт

Как видим, Яндекс нашел 196 проиндексированных страниц. Теперь проделаем то же самое с Google.

Мы получили 1400 страниц в общем индексе Гугл. Кроме основных страниц, участвующих в ранжировании, сюда попадают так называемые «сопли». Это дубли, либо малозначимые страницы. Чтобы проверить основной индекс в Google, нужно ввести другой оператор: site:сайт/&

Итого в основном индексе 165 страниц. Как видим, у моего блога есть проблема с количеством дублей. Чтобы их увидеть, нужно перейти на последнюю страницу общей выдачи и нажать «показать скрытые результаты ».

Снова перейдя в конец выдачи, вы увидите примерно такое:

Это и есть те самые дубли, в данном случае replycom . Такой тип дублей в WordPress создается при появлении комментариев на странице. Есть множество разных видов дублей, их названия и способы борьбы с ними, будут описаны в следующей статье.
Наверняка у вас возник вопрос, почему в Яндексе мы не увидели такого количества дублей, как в Google. Все дело в том, что в файле robots.txt (кто не знает что это, читайте « ») на блоге стоит запрет на индексацию подобных дублей с помощью директивы Disallow (подробнее об этом в следующем посте). Для Яндекса этого достаточно, но Гугл работает по своим алгоритмам и все равно учитывает эти страницы. Но их контент он не показывает, говорит, что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt».
Проверка на дубли страниц по отрывку текста, по категориям дублей
Кроме вышеописанного способа, вы можете проверять отдельные страницы сайта на наличие дублей. Для этого в окне поиска Яндекс и Google, можно указать отрывок текста страницы, после которого употребить все тот же site:my-site.ru. Например, такой текст с одной из моих страничек: «Eye Dropper - это дополнение позволяет быстро узнать цвет элемента, чем-то напоминает пипетку в Photoshop». Его вставляем в поиск Гугл, а после через пробел site:my-site

Google не нашел дублей это страницы. Для Яндекса проделываем то же самое, только текст страницы берем в кавычки «».
Кроме фрагментов текста, вы можете вставлять ключевые фразы, по которым, к примеру, у вас снизились позиции.
Есть другой вариант такой же проверки через расширенный поиск. Для Яндекса — yandex.ru/advanced.html .
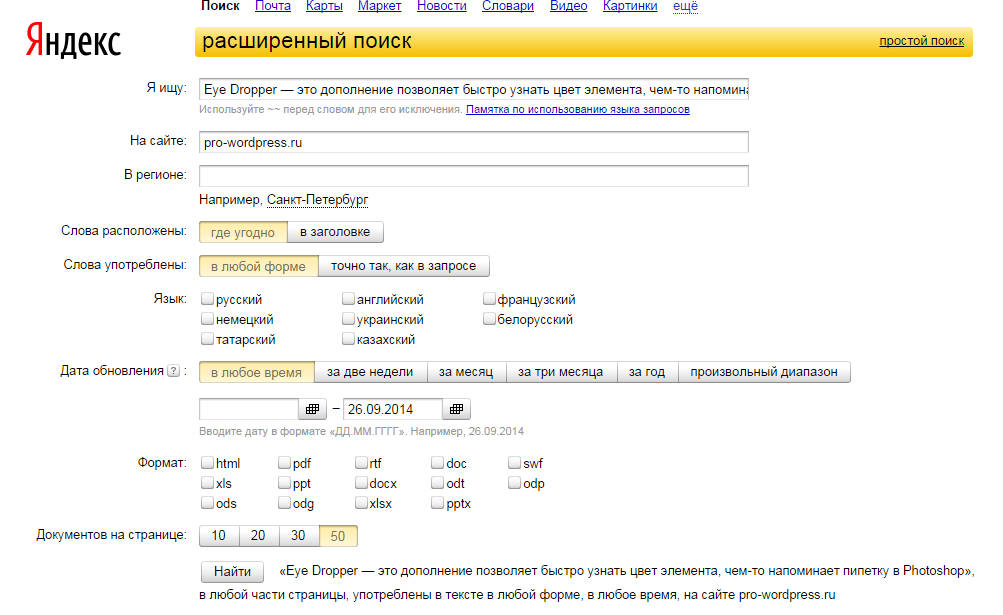
Вводим тот же текст, url сайта и жмем «Найти ». Получим такой же результат, как и с оператором site:my-site .
Либо такой поиск можно осуществить, нажав кнопку настроек в правой части окна Яндекс.
Для Гугла есть такая же функция расширенного поиска.

Теперь посмотрим, как можно выявить группу дублей одной категории. Возьмем, к примеру, группу tag.

И увидим на странице выдачи по данному запросу следующее:

А если попросить Гугл вывести скрытые результаты, дублей группы tag станет больше.
Как вы успели заметить, дубликатов страниц создается очень много и наша задача – предотвратить их попадание в индекс поисковиков.
Поиск дублей страниц сайта: дополнительные способы
Кроме ручных способов, есть также возможность автоматически проверить сайт на дубли страниц.
Например, это программа Xenu , предназначенная для технического аудита сайта. Кроме дубликатов страниц, она выявляет . Это не единственная программа для решения таких задач, но наиболее распространенная.
Также в поиске дублей страниц помогает Google Webmaster, здесь можно выявить страницы с повторяющимися мета-тегами:

Тут вы посмотрите список урлов с одинаковыми тайтлами или описанием. Часть из них может оказаться дублями.
На сегодня все. Теперь вы знаете, как найти дубликаты страниц. В мы подробно разберем, как предотвратить их появление и удалить имеющиеся дубли.
Хочу сделать небольшое добавление ко всему сказанному. Если Вы почитаете в интернете посты некоторых известных блоггеров про то, как убрать дубли в WordPress из поисковой выдачи, то поймете, что разговор выходит довольно длинный , и это действительно так. Даже того, что было проделано в указанных статьях данного блога, недостаточно, чтобы полностью убрать лишний контент из поиска. Т.е. все это работает, но не до конца.
Разобьем сегодняшнюю задачу на части.
- Удаление ненужного заголовка
- Форматирование комментариев
- Работа со страницами с пагинацией
Пройдемся по каждой из них.
Удаление ненужного заголовка
Вот казалось бы, мы пишем новые статьи, отвечаем комментаторам, ставим ссылки на свой блог, прописываем title к картинкам, везде где надо и не надо, но… что-то все равно идет не так, как хотелось бы. Работает все не совсем так, как ожидалось. Гугл нас весело индексирует, думаешь, куда ж он на этот раз впихнет ссылку на проиндексированную страницу… А Яндекс как-то не спешит. Нет, он сам по себе тормознутый неспешный. Может это еще не все?
Так вот было замечено, что автоматически добавляемый к ответу сервера заголовок rel=shortlink Яндекс не любит. Дубль по ней не создается, так как у Вас наверняка прописаны canonical для страниц, да и если вбить ссылку, которая приходит в заголовке (сейчас покажу), в яндексовский сервис «Проверка ответа сервера «, то ответом является 301 Moved Permanently. Видимо, Яндекс воспринимает это как мусор на странице, который ему не нравится.

Мы видим, что заголовок отдается. Но у меня на блоге установлен плагин кэширования , поэтому следующий тычок по кнопке отдает несколько другой набор заголовков, что видно на картинке ниже, так что имейте это ввиду при тестировании.

Чтобы отключить этот заголовок, открываем файл /wp-content / themes / ваша-тема / fuctions.php и пишем перед символами?> всего одну строчку:
remove_action(‘template_redirect’, ‘wp_shortlink_header’, 11);
remove_action (‘template _ redirect’, ‘wp_shortlink _ header’, 11 ) ; |
Сохраняем файл, чистим кэш, если такой плагин у Вас используется, и видим, что заголовок исчез.
Форматирование комментариев
Тут придется поработать побольше, саму проблему стоит разделить на более мелкие кусочки.
- Решение проблемы replytocom
- Что делать с #comment ?
Возьмем с данного блога форму готового комментария и пронумеруем, к чему относятся данные проблемы.

Преобразование ссылки на сайт комментатора в тег span
Несмотря на то, что все URL сайтов комментаторов по умолчанию снабжены атрибутом rel=’external nofollow’, держать открытыми данные URL не есть гуд. Но убирать их совсем тоже нет никакого смысла, поскольку добрую часть ценных комментаторов с блога Вы уберете.
Не будем скрывать, что многие блоггеры оставляют комментарии на других блогах не только для того, чтобы просто оставить отзыв о работе, проделанной автором статьи, но и чтобы на том сайте появилась ссылочка на блог комментатора, по которой можно тыкнуть
. Иными словами, комментатор привлекает на свой блог других людей с Вашего сайта. Увы, не будет и такой возможности, скорее всего, и комментариев почти не будет. Поэтому мы оставим возможность перейти на сайт комментатора, но саму ссылку « Напомню, что у меня шаблон Reverie, необязательно, что код, приведенный ниже, непременно подойдет Вам, нужно лишь понять смысл происходящего . Открываем все тот же файл fuctions.php Вашей темы и перед тегом?> пишем: function remove_tag_a_link($tag_remove) {
$url = get_comment_author_url($comment_ID);
$cut = array(" function
remove_tag_a_link
($
tag
_
remove)
{
$
url
=
get_comment_author_url
($
comment
_
ID)
;
$
cut
=
array
(" $
insert
=
array
(",
" return
str_replace
($
cut
,
$
insert
,
$
tag_remove
)
;
add_filter
("get_comment_author_link"
,
"remove_tag_a_link"
,
"url"
)
;
Данный код элементы одного массива ($cut) заменяет элементами другого массива ($insert). Везде в интернете Вы найдете данный код, в котором в каждом из этих массивов 4 элемента, то есть последний заменяемый элемент в ссылке на сайт комментатора был rel=’external nofollow’. Но дело в том, что в моем шаблоне в теге « Честно говоря, мне тут и добавить нечего, просто дам ссылку на , где подробно описано, как сделать так, чтобы при щелчке на «Ответить» форма ответа выводилась скриптом, встроенным в WordPress, а сам этот элемент страницы перестал быть ссылкой. Если этого не сделать, то мы получаем в поисковых системах кучу дублей replytocom
. И все наши труды по продвижению блога будут выброшены. Поисковики дубли все-таки не любят. Лично я использовала метод добавления функции в файл functions.php, так что можете нажать сочетание клавиш Ctrl + F на странице блога SEO Маяк, скопировать туда имя этого файла, первое его упоминание на странице блога как раз встречается в нужном нам абзаце . Если Вы наведете курсор мыши на дату выпуска комментария, он изображен на рисунке выше, то увидите, что это ссылка, имеющая вид http://наш_сайт/… /#comment-230. И сколько есть комментариев, столько подобных ссылок у Вас будет. Что же с ними делать, скажете Вы?! Ответ: ничего
! Ничего, так как с точки зрения поисковых систем это не дубли, это якори для улучшения навигации по странице. Конечно, если Вы очень захотите, Вы можете удалить эту ссылку, но делать это совсем не обязательно, пусть будет . Если картинки, на которые были постоянные ссылки, все же попали в индекс поисковых систем, то они оттуда нескоро пропадут. По моему опыту, если прописать 301 редирект на них, они начнут массово исчезать из индекса примерно через месяц-два. Раньше ждать чудес не стоит. В статье про удаление постоянных ссылок на картинки я приводила некий скрипт, в котором были прописаны редиректы для страниц с картинками. Когда я стала смотреть ответ сервера на некоторые, все же проскочившие в индекс гугла, страницы с картинками, то обнаружила, что некоторые из них отдают 302 редирект. Такие страницы могут висеть очень долго, так как поисковая система надеется, что может быть страничка еще «очухается», так как недаром данный редирект носит название «временный». Поэтому открываем файл /wp-content / plugins / attachment-pages-redirect / attachment-pages-redirect.php и, если мы столкнулись с подобной ситуацией, просто меняем в функции sar_attachment_redirect строчку wp_redirect(get_bloginfo("wpurl"), 302);
Решение проблемы дублей replytocom
Что делать с #comment ?

Маленькая правка редиректа страниц с картинками


 Настройка и подключение приставки цифрового телевидения
Настройка и подключение приставки цифрового телевидения Настройка и подключение приставки цифрового телевидения
Настройка и подключение приставки цифрового телевидения Беспроводная акустика JBL GO Black (JBLGOBLK) - Отзывы Внешний вид и элементы управления
Беспроводная акустика JBL GO Black (JBLGOBLK) - Отзывы Внешний вид и элементы управления Виртуальный компьютерный музей Dx связь
Виртуальный компьютерный музей Dx связь